Simple. Neural Networks only understand numerical data. Their weights, their biases, and their training, all take place using numerical values, floats, and integers, yada yada. Now when we want to work with words and other textual data, we need a way to convert them to numerical representation, that’s where word embeddings come under the picture.
Natural Language Processing
What is Natural Language Processing? It’s a vast field of science, that comes under the category of linguistics, it has been there even before the recent developments in machine learning and deep learning came into the picture. It comprises techniques like Stemming and Lemmatization – processes used to reduce words to their root form. Named Entity Recognition – identifying and classifying named entities such as person names, organization names, and locations in text, etc. Traditional NER techniques often rely on handcrafted rules and dictionaries to identify patterns and keywords associated with named entities and so on.
Here, at MLDL we would like to look more into the deep learning applications and advancements. That is working on language tasks that involve neural networks. However, we will delve into two types of word embeddings: Traditional/ Non-Deep Learning Based and Modern/Deep Learning Based.
Traditional/Non-Deep Learning-Based Word Embeddings
Before the rapid increase in the applications of deep neural networks or machine learning, natural language tasks were still carried out. It used mathematical and statistical tools for this. There are statistical tools used for word embeddings too, and do not involve deep learning :
Latent Semantic Analysis (LSA)
This is one of the most widely used methods and is used in conjunction with deep learning methods too. We won’t go deep into the math here, as it is quite a vast topic. The main idea is that we start with a term-document matrix, which in other words is a vocabulary*document matrix. Vocabulary here is the unique number of words on your task, and the document could be text, articles, paragraphs, etc, whatever base unit you choose. People mostly choose sentences.
The matrix, let’s say M*N matrix, represents the frequency of each term in the document. A note here, this matrix is mostly sparse, because you won’t expect each word to appear in a given document(assuming the document to be a sentence here).
The term-document matrix is then decomposed into three matrices using Singular Value Decomposition(SVD): U, Σ, and V^T. U represents the relationships between words and latent topics, Σ contains the importance of each topic, and V^T represents the relationships between documents and latent topics.
SVD helps us reduce the dimension to a certain number K which is small and compressed enough to capture the important features. The U matrix obtained, each row of this matrix represents the word embeddings of that vector. This summarises LSA and how it is used for getting word embeddings.
GloVe
Glove stands for Global Vectors for Word Representation. It calculates the co-occurrence matrix which represents the co-occurrence of each word in a given corpus with other words. For example, if a cat and dog occur frequently together( meaning nearby ) in the given corpus, then their co-occurrence count would be high.
After we have calculated the co-occurrence matrix, we then again use SVD to factorize this into the terms U, Σ, and V^T. Following a similar approach as LSA, we get the word embeddings.
Deep Learning-Based Word Embeddings
There are many other methods, but we will only discuss these two methods for traditional word embedding calculation. Now coming down to deep learning-based methods, there are quite a few popular methods :
Word2Vec
There are two types of word2vec models. Both operate using neural networks. The first one that we will discuss here is CBOW or Continuous Bag of Words.
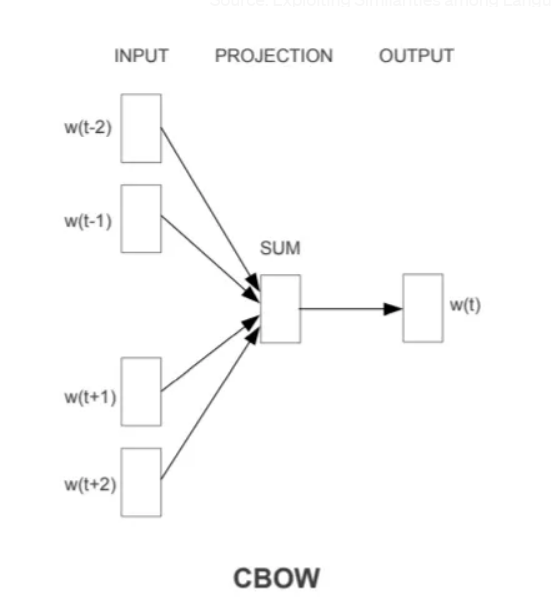
CBOW
The Continuous Bag of Words (CBOW) model is one of the two learning architectures provided by the Word2Vec approach to generating word embeddings, developed by researchers at Google. The CBOW model is designed to predict a target word from a set of context words surrounding it.
In CBOW, we take a word and its surrounding words. This can be any number, from 1 to n. For instance, if the target word is “deep” in the sentence “I am learning deep learning,” and the window size is 2, the context words would be “I,” “am,” “learning,” and “learning.” All of these are encoded as one hot encoding and then fed to the model with the expected output being the vector for “deep”.
Model Architecture
The CBOW architecture can be broken down into the following components:
- Input Layer: This layer consists of the context words. Each context word is one-hot encoded with a size equal to the vocabulary.
- Projection Layer: The one-hot encoded vectors are projected onto a shared hidden layer. Instead of performing a matrix multiplication as typical neural networks do, this projection is simply an averaging of the embeddings of the context words.
- Output Layer: The output layer is a softmax layer that predicts the target word. The softmax function is used to convert the outputs to probabilities, where the target probability is maximized.
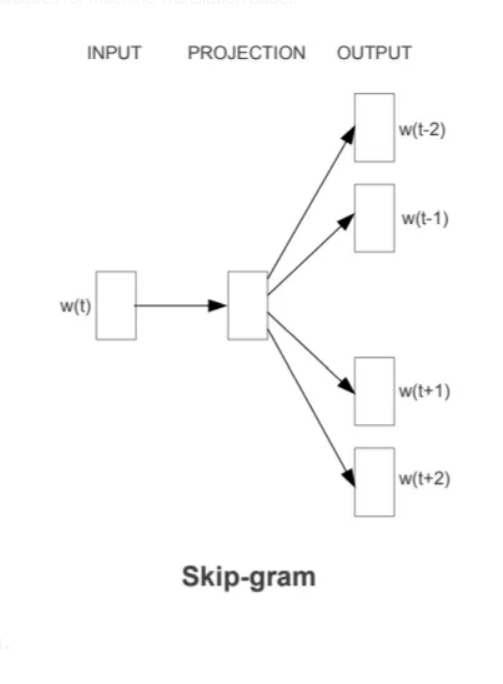
SkipGram
Skipgram works on the opposite principle of CBOW. Instead of predicting a target word based on the surrounding context words, it tries to predict the context words based on a given word. This becomes useful for less frequent words as it samples the surrounding words more efficiently. For example, if the target word is “deep” in the sentence “I am learning deep learning techniques,” and the window size is set to 2, Skip-Gram tries to predict the likelihood of “learning,” “learning,” “am,” and “I” given the word “deep.”
Model Architecture
The architecture of the Skip-Gram model is simple yet effective:
- Input Layer: The input layer takes a single word in its one-hot encoded form. This word acts as the target word from which the context will be predicted.
- Projection Layer: Similar to CBOW, the one-hot encoded input vector is used to retrieve a corresponding dense vector from the embedding matrix. This vector represents the target word and serves as the input to the next layer.
- Output Layer: The output layer is significantly different from CBOW. Instead of a single softmax layer, Skip-Gram has multiple softmax classifiers equal to the number of context words being predicted. For example, for a window size of 2 on each side of the target, there would be 4 softmax outputs. Each softmax predicts the probability distribution over the vocabulary for one context position.
FastText
FastText extends the ideas of Word2Vec to consider subword information, such as character n-grams. It was developed by Facebook’s AI Research (FAIR) lab. This allows the model to capture morphological information (e.g., prefixes, suffixes, and the roots of words) and to generate embeddings for words not seen during training.
Some Other Models
There are other advanced models too that specialize in Word Embeddings. These include BERTs and other transformer-based models that use LSTMS and RCNN structures for this task. We won’t go into much of their detail in this post.
Conclusion
In conclusion, word embeddings are a vital innovation in natural language processing, enabling machines to grasp and process human language with remarkable depth. These techniques have revolutionized how we handle language in technology. As word embeddings continue to evolve, they promise to enhance a wide range of AI applications, making digital interactions more intuitive and impactful. Whether you’re in tech or just curious about AI, understanding word embeddings is essential for anyone looking to keep up with the latest advancements in machine learning.
What’s more? Learn about Generative Adversarial Networks from scratch!