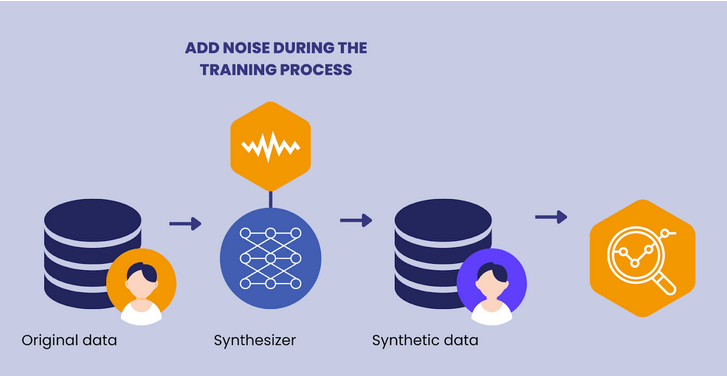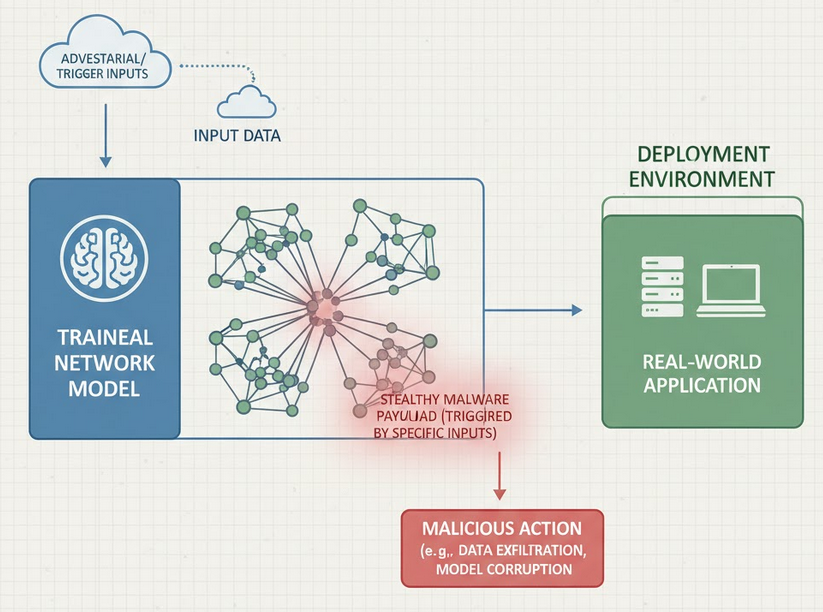
Can You Hide Malware in Neural Networks?
Let us start with something simple. We download a neural network to try out in a project. It might sort images or help with a data pipeline. That model looks like just a file we use and forget. Now imagine that file is carrying a hidden payload. It might sound like a thought experiment, but …