Let us start with something simple. We download a neural network to try out in a project. It might sort images or help with a data pipeline. That model looks like just a file we use and forget. Now imagine that file is carrying a hidden payload. It might sound like a thought experiment, but researchers have shown ways to embed data inside model parameters. That work is often called MaleficNet in the research literature.
We will walk through what that means, why it is surprising, and what it implies for anyone who uses or shares models. We will keep things approachable and avoid deep math. If you like a small technical aside, we include an Optional Nerd Corner that you can skip.
How malware can live inside a model
A neural network is essentially a large collection of numbers. Those numbers, the weights, tell the model how to transform input into output. The idea behind the embedding research is to use those numbers as a place to store data.
Instead of shipping malware as a separate file, someone can split the data into pieces and subtly alter many numbers across the model. The change to any single number is tiny, so the model still behaves as expected. When all the tiny changes are combined, they represent a hidden message.
To borrow from communications engineering, this is similar to spreading a signal across many channels so each channel only carries a little of the information. The benefit for an attacker is stealth. The model still performs well, and at a glance, it looks normal.
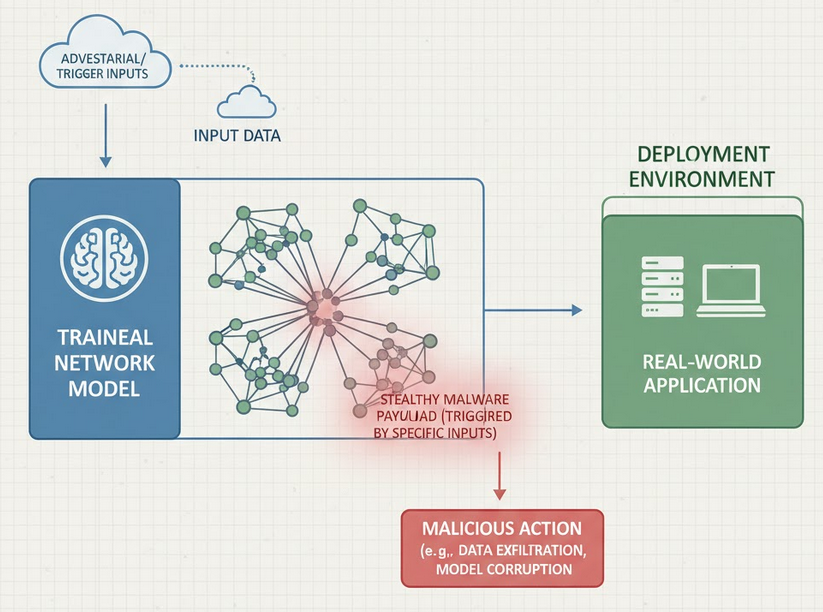
Why is it hard to spot
There are two reasons this is not obvious right away. First, the changes are small and distributed. Anyone’s weight is barely different from what it used to be. Second, most model inspections focus on accuracy and output behaviour. If the model still classifies correctly, many teams stop there.
This combination makes the technique stealthy. A file can live in repositories and be reused by others without raising immediate suspicion.
A gentle look at the recovery problem
It is important to be clear about a distinction. Hiding data in a model is not the same as executing code from it. The hidden data must be extracted and turned into an executable form before it can run. That extraction requires knowing the encoding method and having access to the raw parameters.
So the real risk is a two-part chain. First, the model carries data that is hidden but recoverable if you know how. Second, some process or person with access reconstructs the data and runs it. The researchers show that the first part is feasible and reliable under certain conditions. The second part depends on the operational context and practices.
Quick Math
Optional Nerd Corner: a compact expression is: ̄wj = wj + γ Cj bj
Here, we are only saying that the modified weights are the original weights plus a small added vector that encodes the hidden bits. That is all the equation expresses in one line.
The injection and extraction of ideas, described simply
We will describe the two operations at a high level without step-by-step detail. Think of these as two roles in the story.
Inject is the packing phase. The actor prepares the data to be hidden, takes steps to make it robust to small errors, and then blends it into the model in many small pieces. The goal is to make each change subtle while preserving the ability to recover the full message later.
Extract is the unpacking phase. Someone who knows how the data was blended goes through the model, looks for the faint signals, combines those faint bits into a noisy reconstruction, and then relies on the robustness steps from the packing phase to repair errors and recover the original file. At the end, there is usually a verification step to ensure the recovered file matches what was intended.
The important takeaway is this. The pair of actions is designed to be stealthy in storage and reliable in recovery. That combination is what makes the approach notable.
How can this turn into a real threat?
Embedding itself is only half the story. The risk increases when models are treated with lax operational practices. Here are typical ways the hidden data might become active, described in general terms.
• Someone runs a script or tool that reads raw weights and processes them. If that tool reconstructs the hidden data and then writes or launches it, the payload is executed.
• An automated pipeline that pulls models, converts them, or runs test scripts might accidentally provide the execution path.
• An insider with access to model files could recover and run a payload.
In short, a hidden payload becomes dangerous when a process or person with the right access and knowledge turns it into something that runs.
Practical steps we can take
We want to be careful without making life impossible. These suggestions are practical and easy to adopt.
- Treat external models like code artifacts. Prefer models from trusted sources and verify provenance.
- Avoid running unreviewed example scripts that touch raw weights. Inspect or sandbox them first.
- Use inference as a service where feasible, so raw parameters do not reside on untrusted hosts.
- Limit who can read raw model files. Least privilege helps here.
- Monitor runtime behaviour after new models are loaded. Unexpected network activity or new processes are worth investigating.
These steps reduce the chance that a hidden payload is ever extracted and executed.
Conclusion
We have seen that hiding data inside a model is more than a curiosity. It is a stealthy storage channel with real implications for model sharing and deployment. The technique does not instantaneously give an attacker the power to run arbitrary code. Instead, it changes the risk profile. If access to raw parameters is common and scripts that process those parameters are run without scrutiny, the opportunity for misuse grows.
For us, the takeaway is straightforward. We should treat models as sensitive artifacts and adopt basic operational hygiene. Doing so closes the practical gaps that make an otherwise clever research idea into a real operational risk.