Autonomous vehicles need to classify road conditions in real time. Wet roads, icy surfaces, severe potholes. The model needs to know so the vehicle can adjust speed, traction, suspension before it gets there.
Training that model needs data. Lots of it. From lots of different roads, weather conditions, geographies. You could collect it all centrally, but then every vehicle is uploading raw camera footage to a server somewhere. Privacy problem. Bandwidth problem. Increasingly a legal problem. GDPR, CCPA, PIPL all push back against bulk data aggregation. The differential privacy post covers that regulatory picture if you want to go deeper.
Federated learning solves it. Each vehicle trains locally, sends only the model update to a central server, server aggregates into a global model, sends it back. No raw data leaves the vehicle. Privacy preserved. Distributed compute used.
Clean solution. Real problem solved.
Except now you have a new attack surface. Any vehicle that participates can influence the global model. And you cannot check their data. That is the whole point of the privacy guarantee. That tension is exactly where label flipping attacks in federated learning live.

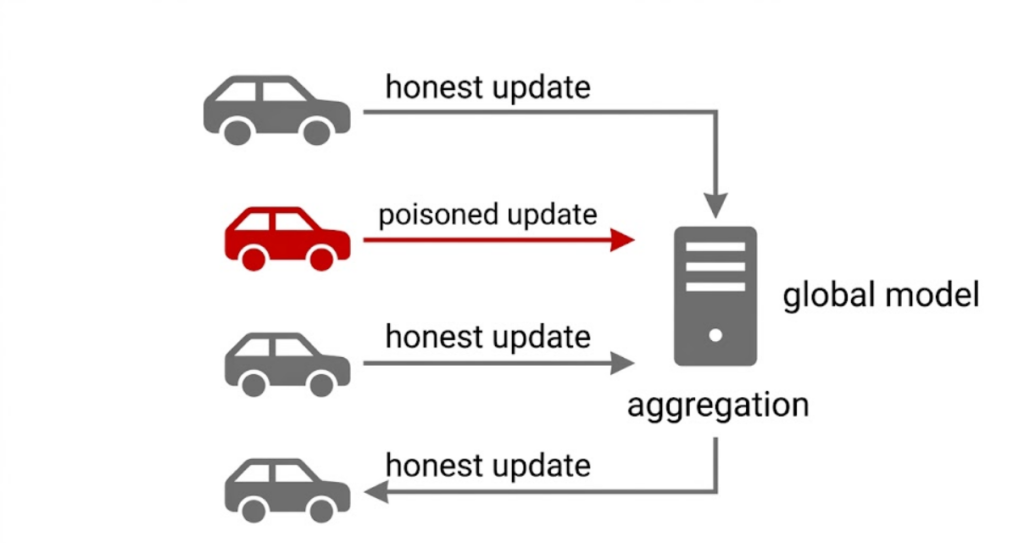
The Attack Is Simpler Than You Think
Label flipping. That is it.
A compromised vehicle takes its local dataset and changes the labels on a specific class. Severe uneven roads get relabelled smooth. The images stay exactly the same. Just the label changes.
Vehicle trains on this poisoned data. Generates a model update that has learned the wrong association. Sends it to the server. Server aggregates it with honest updates from other vehicles. Over enough rounds the global model starts believing that severe uneven roads look smooth. During inference a real vehicle hits an actual uneven road and calls it smooth. Does not adjust speed. Does not recalibrate suspension. The road is dangerous and the model is completely blind to it.
Without any defense, this attack drops source class recall by 43% and pushes attack success rate above 30%. Nearly a third of genuinely dangerous roads getting misclassified as safe. That is not theoretical. That is what the numbers show.
Compare this to backdoor attacks which require manipulating actual image pixels, adding invisible noise or a trigger patch that causes misclassification only when present. Label flipping needs none of that. Change a text label. Run local training. Done. Any compromised vehicle with basic compute can execute it. That is why it is the practical threat in real deployments.
Three Questions Every FL Defense Must Answer
Here is where most writeups on FL security go wrong. They evaluate defenses on one number. Does attack success rate go down, yes or no. Single metric. Done.
That is the wrong frame.
The right frame is three questions. Any defense that cannot answer all three is incomplete by definition. And the incompleteness has real consequences.
Question 1: Can you detect poisoned model updates this round?
This is where most defenses focus. Clustering, cosine similarity, statistical filtering. Different methods, same goal. Identify which submitted models look malicious and exclude them from this round’s aggregation.
Necessary. Not sufficient.
A malicious vehicle that gets detected this round just comes back next round. Detection without exclusion is whack-a-mole. You stop the damage today. The attacker shows up tomorrow.
Question 2: Can you permanently exclude persistent bad actors?
Some defenses add a filtering step. Flag a vehicle enough times, stop selecting it. Closer.
Still not sufficient.
By the time you exclude a vehicle after several rounds of flagging, it has already contributed poisoned updates for those rounds. Some of those slipped through detection. That damage is already sitting in the global model’s weights. Exclusion stops future damage. It does nothing about the past.
Question 3: Can you undo historical damage already inside the global model?
This is the question almost nobody asks. And it is the one that determines whether your defense actually restores the model to healthy performance or just stops it getting worse from this point forward.
Detection answers question one. Exclusion answers question two. Remediation answers question three.
Most published defenses stop at question one. A handful reach question two. FedTrident, out of KTH Royal Institute of Technology, answers all three. The full paper is here on arxiv.
Module 1: Detection, Two Neurons at a Time
Most detection methods look at the whole model update and ask whether it looks suspicious overall. The problem in a real Non-IID federated learning environment is that legitimate updates already look wildly different from each other. Every vehicle drives different roads in different weather. Suspicious and legitimate overlap completely when you look at the full model.
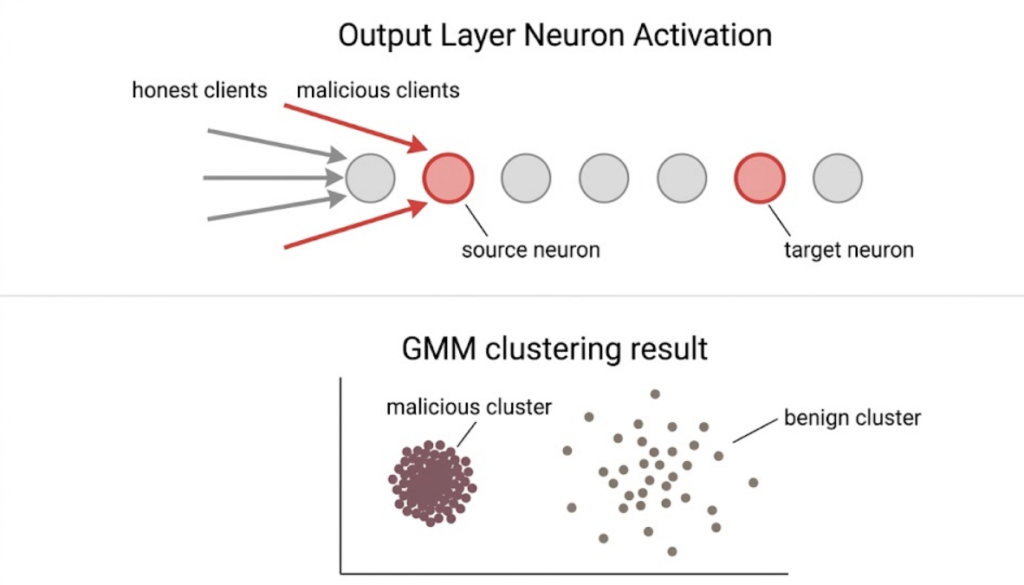
FedTrident narrows the focus dramatically. Instead of the whole model it looks at individual output layer neurons and asks: which two neurons are being fought over hardest this round?
Every output neuron gets a score each round. Two signals combined.
Magnitude. How much did this neuron’s connected weights move across all clients combined. And angular inconsistency. Each client’s update for a neuron is a vector of individual weight changes. Compute the average direction across all clients. Measure how much each client deviates from that average. High deviation means clients are pulling this neuron in conflicting directions.
Combined score: magnitude multiplied by (1 + inconsistency).
A neuron where everyone agrees, high magnitude low disagreement, is just a class everyone has strong legitimate data on. Normal. A neuron where magnitude is high AND clients are pulling in conflicting directions is the attack fingerprint. Honest clients pushing it one way based on real images. Malicious clients pushing it the other way based on mislabelled images.
Top two scoring neurons get selected as suspected source and target. One thing worth noting: the paper bakes in a directionality assumption here. The lower-indexed neuron is always treated as source, the higher as target. This reflects the assumption that safety-critical attacks flip from more hazardous classes to less hazardous ones, uneven to smooth, water to dry, not the reverse. If an attacker flipped the other way, making the model more cautious rather than less, the detection logic would still catch them but the labelling would invert.
FedTrident then extracts just the weight change vectors connected to those two neurons from every client’s update. Feeds them into a Gaussian Mixture Model. Two clusters emerge. The denser tighter cluster gets flagged as malicious and excluded before aggregation.
Why does density indicate malicious? Honest clients have genuinely varied data. Their weight updates naturally spread out even when pointing broadly the same direction. Malicious clients are all executing the same operation, same label flip, same wrong signal. They converge tightly because they are doing the identical wrong thing.
Concrete example. Five vehicles. A drives city centre, mostly smooth asphalt. B drives a mountain route, lots of uneven terrain. C drives motorway, mixed conditions. D and E are compromised, both flipping severe-uneven labels to smooth. Round one. Smooth and severe-uneven neurons light up. High movement, high directional conflict. D and E’s deltas cluster tightly together. A, B, C spread out based on genuinely different road experiences. Dense cluster flagged. D and E excluded. A, B, C aggregated into the new global model.
One more thing worth noting. The detection signal gets stronger as training progresses. As the global model gets better at classifying hazardous roads correctly, honest clients produce smaller stable gradients on those neurons. Their predictions are already right, loss is low. Malicious clients are fighting an increasingly competent model, so their loss stays high and their gradients stay large and directionally conflicting. The attack becomes more detectable over time. The detection mechanism partially self-improves.
But this cuts the other way in early training. When the model knows nothing, forward passes produce confused low-confidence outputs. Loss is moderate for everyone, honest and malicious alike. Malicious gradients do not stand out yet. FedTrident’s detection is weakest in early rounds, exactly when poisoning has the most impact on shaping the model’s trajectory. The paper does not address this directly. Worth knowing if you are building on this.
Module 2: Exclusion, Adaptive Rating
Detection handles the current round. Exclusion handles the attacker who keeps coming back.
Every vehicle carries a rating score between 0 and 1. Starts at 0.80. Updates every round based on detection results.
Flagged as malicious, score drops by 0.15 multiplied by how many consecutive rounds it has been flagged. First flag costs 0.15. Second consecutive flag costs 0.30. Third costs 0.45. A vehicle submitting poisoned updates bleeds out progressively faster. Cleared as benign, score recovers by 0.05.
The asymmetry is intentional. Penalty is three times the reward. A malicious vehicle trying to alternate clean and poisoned rounds still trends toward zero, just slower. An honest vehicle with occasional noisy updates due to limited local data recovers without being permanently penalised.
Hit zero. Blacklisted. Never selected again.
Module 3: Remediation, Machine Unlearning
Blacklisting fires the cleanup.
Throughout training the server tracks each vehicle’s accumulated contribution. A running cumulative sum of every update they contributed in rounds where they were not filtered out. Low storage cost. One accumulated delta per client, updated each round.
When a vehicle gets blacklisted, the server subtracts that accumulated sum divided by the average good client count per round from the current global model. Mathematically removing their direct historical influence from the weights.
It is an approximation and the paper is honest about that. Here is precisely why.
At each round the malicious client’s update was diluted by 1/M during aggregation. Subtracting 1/M of their accumulated delta approximately reverses that direct influence. But every round that poisoned global model went out to honest clients, they trained on it. Their gradient updates in subsequent rounds were computed on a corrupted loss landscape. The poisoned weights shifted their activations through every forward pass, which shifted their backpropagation gradients. That secondary contamination is baked into the honest clients’ updates sitting in the global model. The subtraction does not touch it.
To remove it fully you would need the counterfactual. What the global model would have looked like at each round had the attacker never been there. That was never computed. You cannot reconstruct it without retraining from scratch, which defeats the purpose.
So remediation is a slightly stronger claim than the math fully supports. What you actually get is cleaner, not clean. The attacker’s direct fingerprints come out. The downstream corruption baked into honest updates through training on a poisoned model stays. In practice the ablation numbers show the remediation module adds real performance on top of detection and exclusion alone. Every module is doing work. But full restoration it is not.
What The Numbers Actually Show
Three numbers on ResNet-18 for the Friction task.
FedAvg with no defense under attack: source recall 44.88%, attack success rate 30.85%. Nearly a third of dangerous roads misclassified as safe.
Best prior defense DEFEND under the same attack: source recall 74.20%, attack success rate 2.84%. Real improvement. Still a gap to attack-free performance.
FedTrident: source recall 88.04%, attack success rate 1.72%. Matches or exceeds attack-free performance.
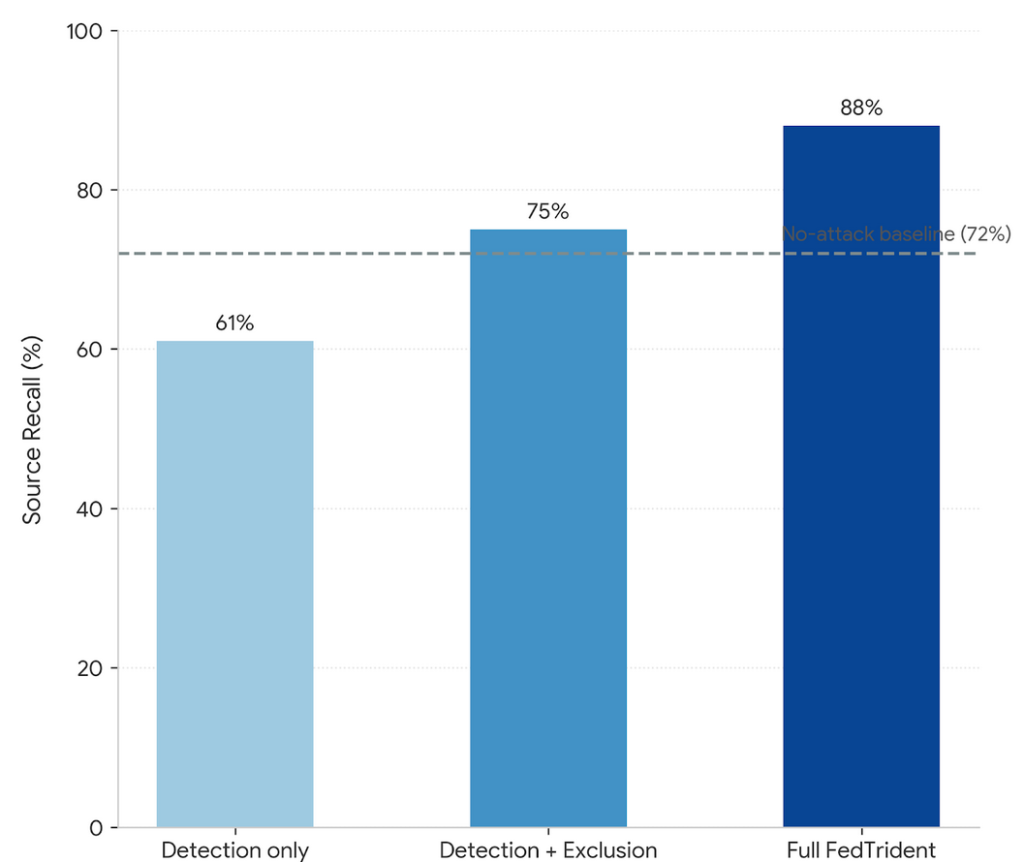
The ablation is where it gets interesting. Each module tested in isolation across three architectures:
- Detection alone: source recall 61 to 74% depending on model
- Detection plus exclusion: 75 to 81%
- Full system with remediation: 82 to 88%
Every module earns its place. The three questions are not redundant.
One metric worth calling out that most FL security papers skip entirely. GAS, Global Accuracy of Safety. Standard accuracy treats all misclassifications equally. GAS weights them exponentially by how dangerous the error actually is. Calling ice dry gets penalised far more than calling wet slightly damp. FedTrident leads on this metric too, which matters more than raw accuracy in a safety-critical deployment.
Experiments ran across six architectures and three RCC tasks using the RSCD dataset, one million real road surface images from vehicle-mounted cameras. The FL training framework is available on GitHub.
What The Framework Does Not Yet Solve
Being honest about this.
The early training window. Detection reliability is not uniform across training. Early rounds have higher gradient variance. The network has not yet formed meaningful feature representations, GMM cluster boundaries are fuzzier, detection is less reliable. That is exactly when poisoning has the most impact on shaping the model’s trajectory. And the unlearning step is least able to undo trajectory effects baked in during those early rounds. The framework is weakest precisely when it matters most.
The adversary model is naive. The paper assumes malicious vehicles naively flip labels and submit poisoned gradients without any evasion strategy. A sophisticated adversary who reads this paper can compute what an honest gradient should look like on those two neurons. They have the global model each round. They can run a forward pass on correctly labelled data, observe the expected gradient magnitude and direction, then scale or blend their poisoned gradient to match those statistics before submitting. Against FedTrident’s detection this means a poisoned update that looks statistically honest. The GMM cluster tightness breaks. The rating system offers partial protection but a sophisticated attacker who carefully scales updates to stay just below the detection threshold can maintain a healthy rating while slowly poisoning the model.
The 50% ceiling. The system assumes malicious vehicles are a strict minority. Above 50% the clustering logic inverts. The dense cluster starts being the honest group. The paper tests up to 40% malicious rate and holds up well. Beyond 50% there are no guarantees.
The Takeaway
Detect. Exclude. Remediate. That is the complete framework. Any defense you evaluate going forward, map it to those three questions. Where does it stop? What does that leave exposed?
FedTrident is the current reference point for FL security in safety-critical road classification. If you are working on federated learning for autonomous systems, medical imaging, infrastructure monitoring, any domain where a misclassification has real consequences, this is the paper to understand before you build your defense strategy.
Future posts here will map new attacks and defenses onto this same framework. That is the lens we are working with going forward.
FedTrident: Resilient Road Condition Classification Against Poisoning Attacks in Federated Learning, Sheng Liu and Panagiotis Papadimitratos, KTH Royal Institute of Technology, arXiv:2603.19101